
Archive.
【Big Data 日本語】 할 말을 찾을 때 채워넣는 추임새 Top 13 본문
감동사/필러 Top 13
| rank | lForm | lemma | pos | subLemma | wType | frequency | pmw |
| 8 | エー | えー | 感動詞-フィラー | 和 | 172070 | 23004.7088327 | |
| 18 | アノ | あの | 感動詞-フィラー | 和 | 81548 | 10902.4699012 | |
| 19 | マー | まー | 感動詞-フィラー | 和 | 79812 | 10670.3772962 | |
| 43 | エート | えーと | 感動詞-フィラー | 和 | 28303 | 3783.9383628 | |
| 47 | アー | あー | 感動詞-フィラー | 和 | 24610 | 3290.2068017 | |
| 48 | ソノ | その | 感動詞-フィラー | 和 | 23543 | 3147.5554138 | |
| 57 | ンー | んー | 感動詞-フィラー | 和 | 16616 | 2221.4577902 | |
| 69 | オー | おー | 感動詞-フィラー | 和 | 12331 | 1648.5794422 | |
| 103 | ウー | うー | 感動詞-フィラー | 和 | 8010 | 1070.8881139 | |
| 150 | イー | いー | 感動詞-フィラー | 和 | 4403 | 588.6542279 | |
| 234 | ト | と | 感動詞-フィラー | 和 | 2836 | 379.1558915 | |
| 795 | ウント | うんと | 感動詞-フィラー | 和 | 712 | 95.1900546 | |
| 3566 | アート | あーと | 感動詞-フィラー | 和 | 95 | 12.7009202 |
일본에서 사용되었던, 되고 있는 모든 말을 알고, 쓸 수 있다면 얼마나 좋을까.
일본 국립국어연구소(한국의 국립국어원 격)는 그 토대를 만들었다.
대상이 된 데이터는 출판된 서적, 잡지, 신문과 도서관에 존재하는 서적,
특정한 목적으로 작성된 백서, 교과서, 광고지, 베스트셀러,
야후! 지식인, 야후! 블로그, 운문, 법률 관련 문서, 국회 회의록이다.
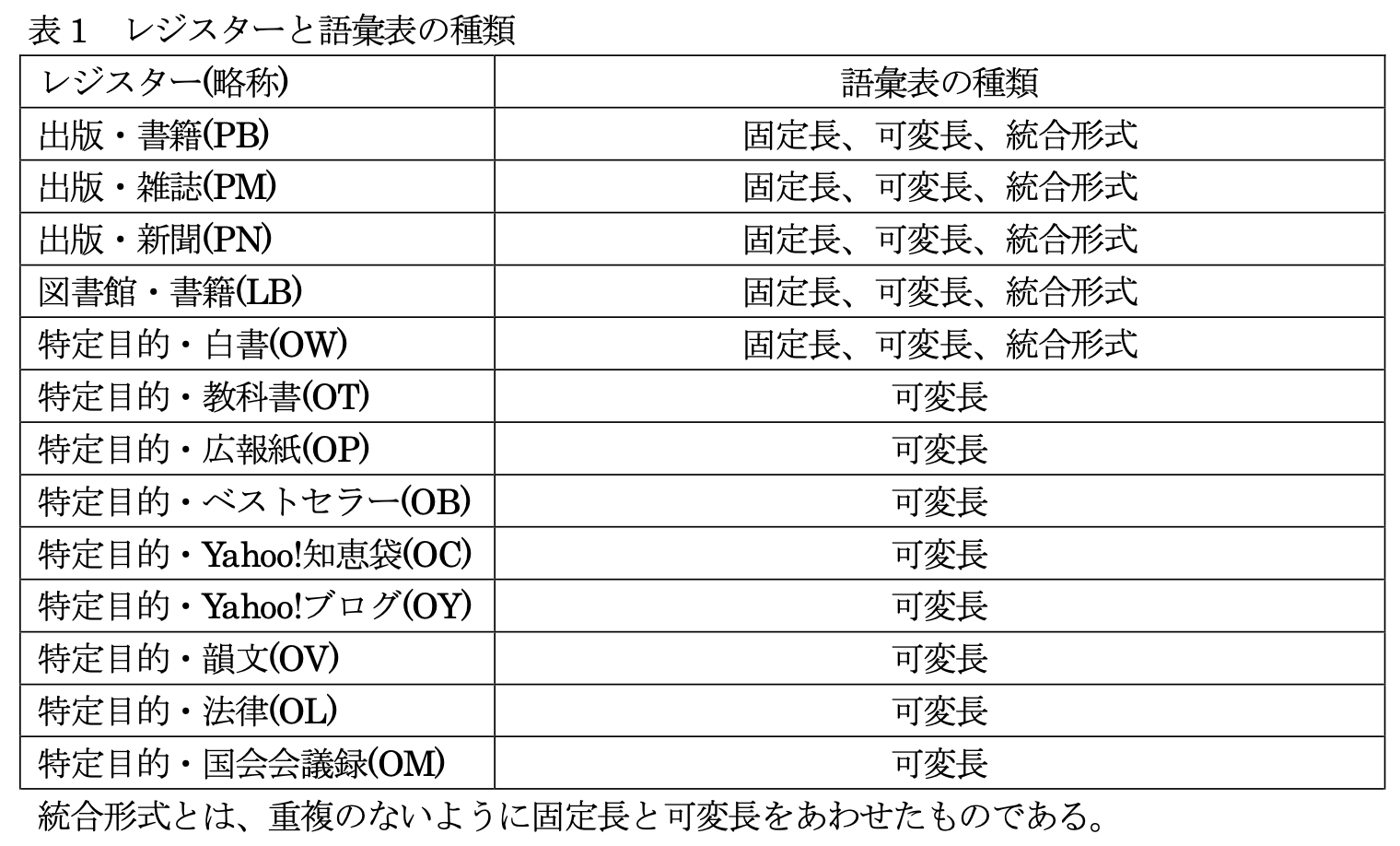
일본 국립국어연구소의 <現代日本語書き言葉均衡コーパス> 프로젝트의
장단문서 총합 2억 개에 가까운 코퍼스, 코어 데이터 2백만 코퍼스를 추려낸 분석 결과물을 참조해,
【Big Data 日本語】를 연재한다.
'즐거운 일본 탐구' 카테고리의 다른 글
| 【日本探求】 일본의 경영・경제・정책 싱크탱크 사이트 모음집 (0) | 2021.08.11 |
|---|---|
| 【日本探求】 일본 성씨 순위 Top 500 (1) | 2021.08.11 |
| 【日本探求】 자민당 집권세력의 배후 - 일본회의와 신사본청 (0) | 2021.08.08 |
| 【日本探求】 2021 미래의 일본을 앞당긴 언론 보도들. (0) | 2021.08.08 |
| 【日本探求】 일본개헌, 「자민당 헌법 개정안」12가지 핵심 포인트 (0) | 2021.08.07 |
'즐거운 일본 탐구' Related Articles
more



Comments